Machines can analyse vast volumes of data at incredible speed, and accuracy beyond the cognitive range humans can muster. AI amplifies our capabilities and frees up work that requires uniquely human skills, such as professional judgment, creativity, and customer empathy. Simply put, machines and experts do more together than either can do alone.
Building a Legal Data Strategy
AI software is only as good as the data it analyzes. Where does all that data come from? How do we know it’s the data we need?
To answer these questions and many others, we need a data strategy: a comprehensive, top-down approach that organizes and manages an organisation’s data to effect impactful change. We want data on our cases and customers, data on personnel and communication, data about resources, and data about risk management and uncertainty. Any record of fact that we have, we can use to elevate our business.
We often view the different aspects of an operation as discrete and separate entities. Without a data strategy, we may miss the tiny patterns within the operations of a business, analysis that can take place if the organisation’s data is well organized. A legal data strategy focuses on developing data collection and capabilities to improve the quality and efficiency of an organization’s operations.
A good data strategy takes an inventory of an organisation’s goals and resources, both human and technological. Neither people nor tech tools can function well in an organisation where data management is not strong.
Types of Data
There are two types of data: structured and unstructured. Examples of structured legal data include billing records, docket records, and litigation outcomes. This data already possesses a semblance of organization. Unstructured data, on the other hand, typically doesn’t have any kind of internal structure. Examples of unstructured data include court filings, contracts, deposition transcripts, and other documents that are considered mainly for their internal content but are not often separate data points in a larger set. To bring structure to unstructured data like contract data, we can use AI.
Managing Legal Data
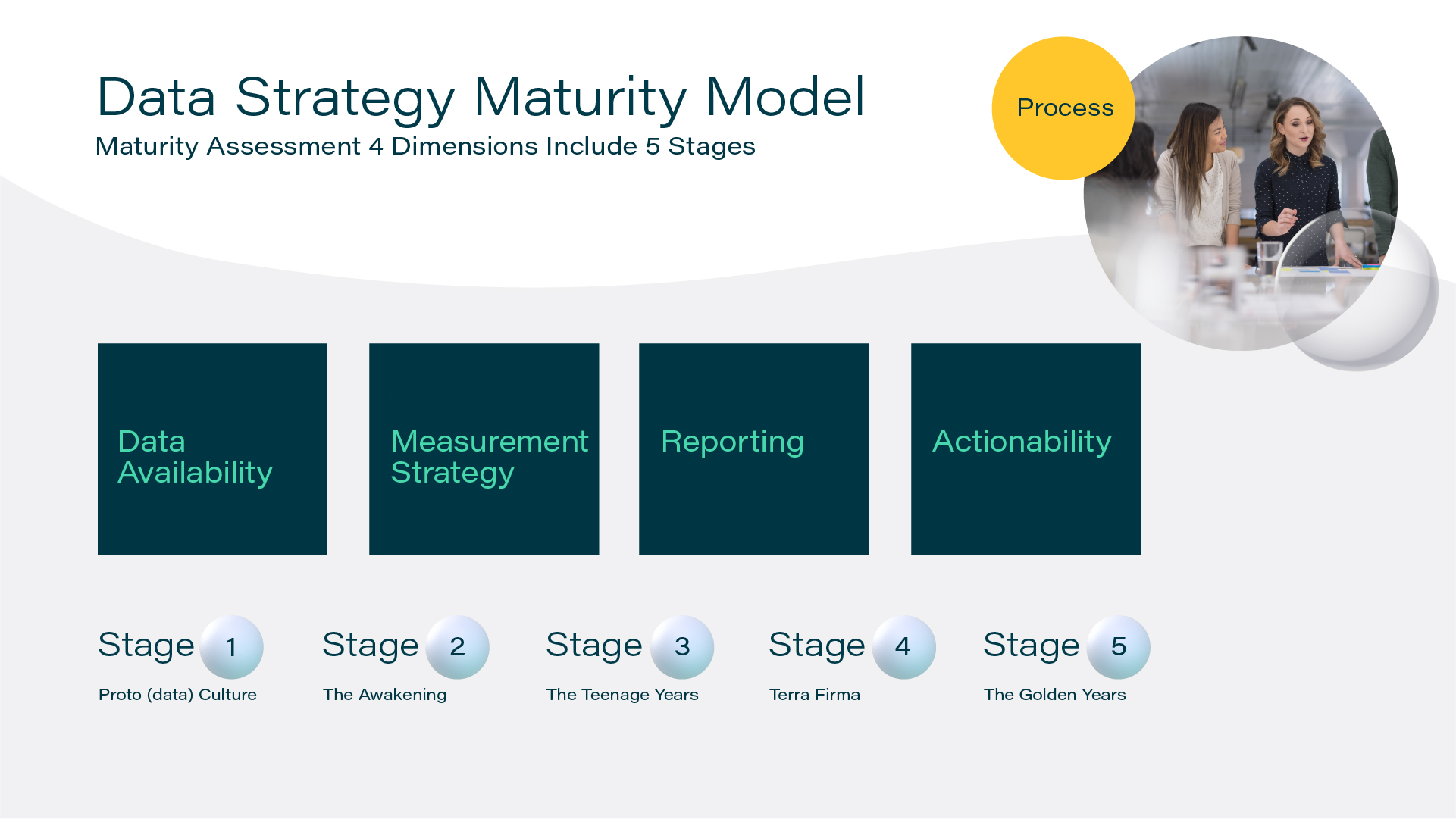
It’s easy to talk about data in the abstract because data is somewhat abstract. To convert unstructured data into useful, structured data, organizations should adhere to the following four elements:
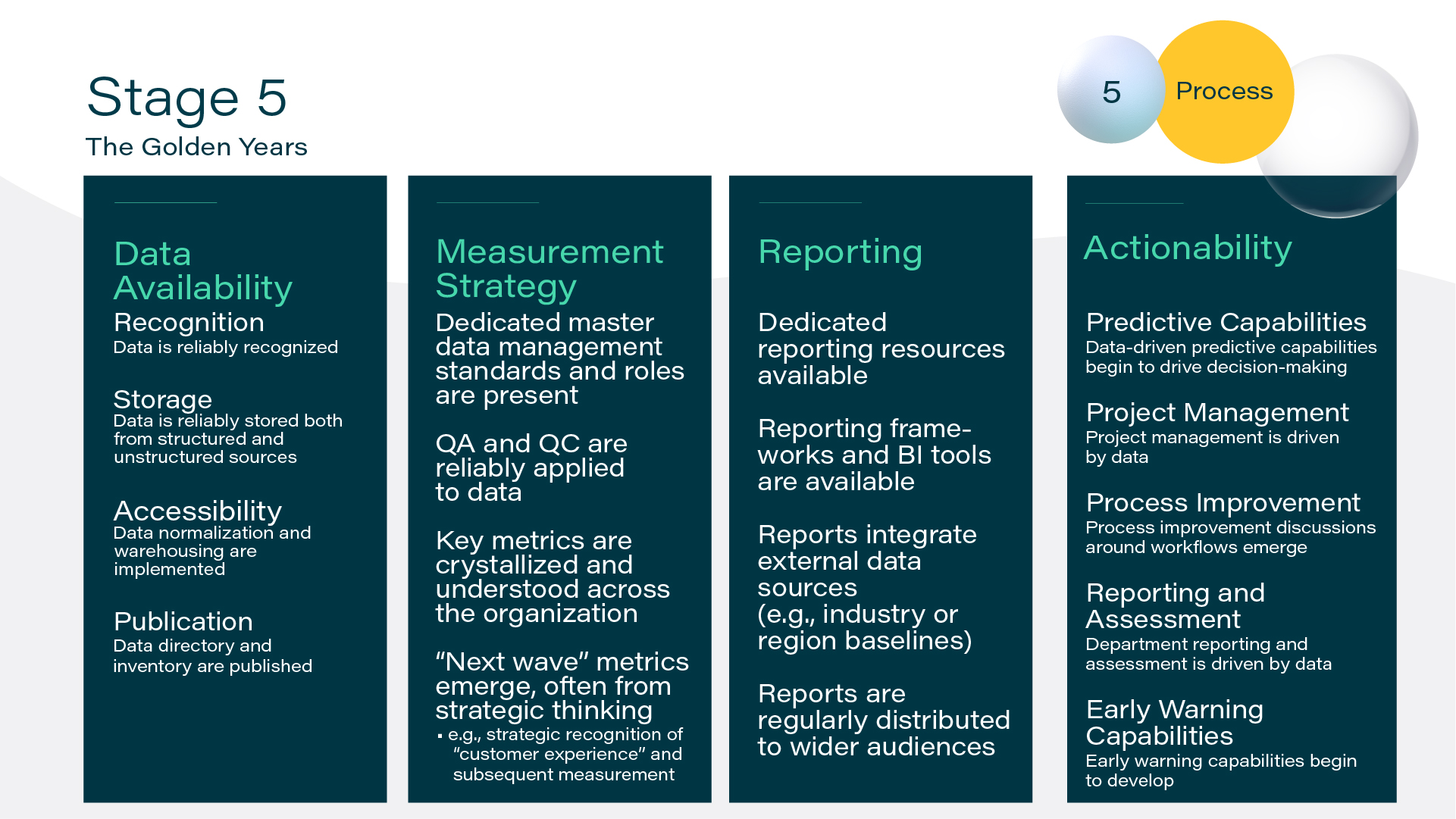
- Recognition: Is useful or relevant data recognized as such? What are we potentially ignoring?
- Storage: Is relevant data being effectively organised and stored?
- Publication: Are there directories of all data? How are these directories structured and organized?
- Accessibility: Who has access to the data? How is the data used? Does everyone know how to find the data they need?
A good data strategy moves through these four stages in a cycle. Each aspect leads directly into the others, allowing for constant improvement and iteration.
Recognition
The recognition stage of a legal data strategy is the first integration point between people and technology. Recognizing relevant, valuable data in your organization is not always easy, but many tech tools make it easier. In emails, Google, Outlook, and other services keep track of metadata and content. For contracts and other documents, solutions that scan data in documents can automatically recognize many types of data.
Using software for data recognition is important, but legal, technology, and business professionals must also work together to address what kinds of data the organization has, what types of data are needed, and whether current capture methods are getting the job done.
Storage
The second stage of the cycle is data storage. We gather data to make predictions about the world. The more data we collect and the longer we collect it, the more confident we can be that our predictions will be accurate; this is why data storage is so important. Organizing data in a meaningful way can be accomplished with technology tools, but having a data strategy creates the conditions under which the people in an organization actively store and manage their structured and unstructured data.
Accessibility
Once an organization has begun recognizing and storing data, the next stage of the cycle is to make the data appropriately accessible. Unstructured data needs to be processed to become structured data, and the application of standard forms or tags reduce redundancy and improve data integrity. Practical accessibility means having a clear system for retrieving, analyzing, extracting, transforming, and otherwise managing data.
Publication
The final stage of the cycle involves the actual usage of data to produce tangible results. Publication doesn’t necessarily mean that an organization is publishing and releasing company data for the whole world to see (although this often does happen in SEC filings, earnings reports, press releases, etc.) Instead, publication refers to maintaining a directory of data within an organization. A software tool can aid in this process. Attention to the default method of organizing data and the best way for your organization to communicate important data internally (e.g., some document management systems build helpful diagrams and charts to communicate an understandable message about a particular subject) is important.
Publication focuses on communication. What is our data telling us? What conclusions can we draw from an analysis of all this data? Many actionable insights come from this stage.
Data Science in Law
Data science uses analytical techniques to better understand, diagnose, forecast, and predict business outcomes. Virtually every industry now collects data about what they do and how they do it. This ubiquity of data collection means that the world is becoming increasingly quantified. The legal industry, while lagging behind others, is not immune from this trend. There are a variety of reasons why legal lags behind:
- Data collection has been limited thus far, especially for law firms;
- Few lawyers have quantitative/science backgrounds, so they are less aware of the value of data and haven’t conditioned their ‘data muscles’;
- The legal industry is fragmented, and there is a wide array of work undertaken at a typical large firm or corporate law department; and
- Up to this point, most systems that collect data have offered less-than-ideal user experiences, affecting adoption
Law departments and law firms that do not collect and analyze their data stores will be left behind when trying to mitigate risk, better predict and achieve outcomes, improve the customer experience, and reduce costs. Some forward-thinking corporate law departments and law firms have created formal roles for legal data scientists. We work with their legal and risk teams to design and implement data strategies and new techniques to harness value from their data.
Corporate law departments got an early start on law firms because in-house teams have amassed more data in corporate systems, and increasingly law is integrated into the business. Law firms have been catching up. Most are focused on modernizing reporting or have clients driving their activity. Opportunities for strategic, systematic investment abound, such as systematically tracking outcome and settlement data for all a firm’s litigation work. Data science and predictive analytics capabilities are starting to be prioritized more by law firm leadership.